|
|
| weblog/wEssays | home | |
|
Flattening the Knowledge Curve: The "Googling" Effect (May 2005) Take a look at the following graphs: 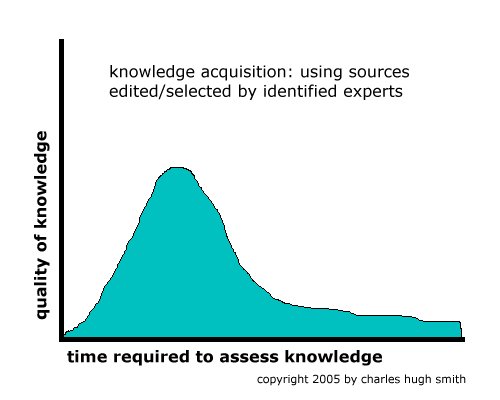
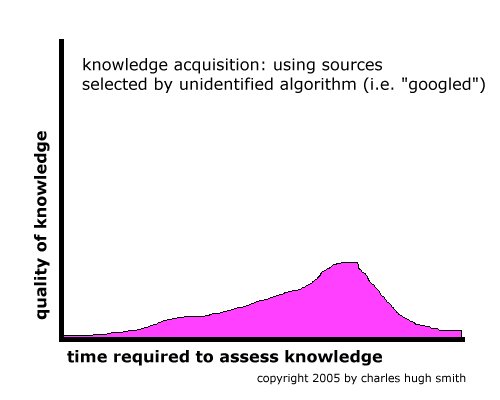
The first graph shows that if you're entering an area of knowledge which is new to you, it takes little time to access key sources which have been edited or selected by scholars, critics or experts whose credentials or experience is public knowledge. The quality of the knowledge is thus high; if you find a supposed expert is biased, it's short work to find a worthy substitute. The net result is that any neophyte can gain high-quality knowledge in a short period of time. After the initial survey, the quality of the knowledge drops as primary sources are absorbed and the search extends into secondary sources. In the alternate global Web-search world we are now entering, the ranking of the various sources of knowledge (websites) is done by a commercially protected, closely guarded algorithm. Since we cannot know how the search engine picked the highest "matches" to a search query, we cannot assess the quality of the knowledge (or the accuracy of the information--and those are two separate issues) until we have scanned many sources and sought out those which can summarize or assemble the most credible sources. This takes time, and still produces low-quality knowledge--knowledge which may contain untrustworthy or even misleading information--because the selection is being performed by a neophyte, i.e. the user. Note also that the quality of the knowledge drops off after a plateau as the sheer volume of secondary information overwhelms the user. Google has stated the goal of digitizing all the world's knowledge, and suggested this might take 300 years. Predictably, the European Union is in a panic, lest the English-speaking American hyperpower dominate not just all the world's commerce and sea lanes but information itself. The question is: will access to such a vast sea of information make us smarter, or will it simply perfect the distraction that the Web already provides? A similar question is raised by the drop in newspaper readership and the rise of blogs. Is the knowledge gained on a blog truly equivalent to that which has been screened by editors or experts? It is quite a stretch to claim "yes." If you want to know more about Japanese films, where should you spend your precious time? Reading Donald Richie or scanning somebody's list of "favorite Japanese films"? (such as mine) Some of each, no doubt, but the latter is no substitute for the former. Put another way: information is not equivalent to knowledge, and relying on a secret algorithm to index, sort and rank information into a simulacrum of "knowledge" is not the same thing as actually understanding a complex topic, or being able to assess the value of a point of view or argument. What are these charts based upon? Nothing but my views. But then I'm not claiming to have gathered any hard data; if I did, would you value the charts more? If I claimed to be an expert, would you put more stock in the charts? How do you know I'm not an expert? In a world of automated search engines without editors or recognized experts to help us sort the wheat from the chaff, then the task of sorting huge quantities of facts and opinions falls to each of us-- an impossible task. Maybe the Standard Hype about how wonderfully the Web is expanding human knowledge has it backwards; perhaps this flattening of the knowledge curve is providing the illusion of knowledge rather than the real goods. * * * copyright © 2005 Charles Hugh Smith. All rights reserved in all media. I would be honored if you linked this wEssay to your site, or printed a copy for your own use. * * * |
||
| weblog/wEssays | home |